「编译原理」中期笔记整理
本文最后更新于:2023年4月15日 晚上
对前半学期的编译原理做小小的整理
1 | 绪论部分
1.1 | 编译器与解释器
- 语言翻译的两种基本形态
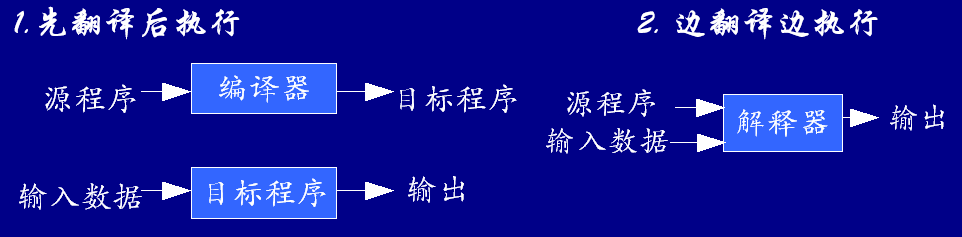
- 编译器和解释器的区别
| 效率 | 空间 | 可移植性, 交互性 | |
|---|---|---|---|
| 编译器 | 高 | 小 | 差 |
| 解释器 | 低 | 大 | 好 |
1.2 | 编译器的工作过程
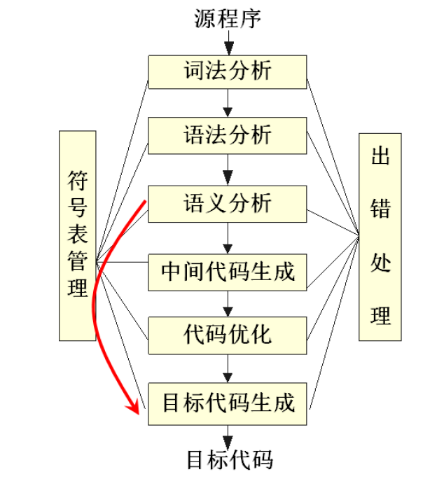
各阶段工作的归纳:
词法分析:识别单词,至少分以下几大类:关键字(保留字)、标识符、字面量、特殊符号;
语法分析:得到语言结构并以树的形式表示;
语义分析:考察结构正确的句子是否语义合法,修改树结构;
中间代码生成(可选):生成一种既接近目标语言,又与具体机器无关的表示,便于优化与代码生成;
(到目前为止,编译器与解释器可以一致)
中间代码优化(可选):局部优化、循环优化、全局优化等;优化实际上是一个等价变换,变换前后的指令序列完成同样的功能,但在占用的空间上和程序执行的时间上都更省、更有效。
目标代码生成:不同形式-汇编、可重定位、内存形式;
符号表管理:记录符号信息并合理组织,便于各阶段查找、操作等;
出错处理:错误的种类-词法错、语法错、静态语义错、动态语义错。
1.3 | 部分概念解释
1.3.1 | 前端和后端
前端指词法分析, 语法分析和语义分析, 中间代码生成部分
后端指代码优化和目标代码生成部分
1.3.2 | 遍
对程序完整分析一遍的工作模式称为「一遍扫描」
一个编译过程可以由一遍、两遍或多遍完成。 所谓「遍」,也称作「趟」,是对源程序或其等价的中间语言程序从头到尾扫描并完成规定任务的过程。
2 | 词法分析
2.1 | 术语解释
- 模式(patten):产生和识别元素的规则
- 记号(token):按照某个模式(或规则)识别出的元素(一组)
- 单词(lexeme):被识别出的元素自身的值(一个),也称为词值
- 语言: 语言L是有限字母表∑上有限长度字符串的集合。
字母表是符号的非空有穷集合。任何语言都有自己的字母表。
例如,Pascal语言的字母表为:
∑={A~Z, a~z, 0~9, +, -, *, /, <, =, >, :, ‘, ”, ;, ., ↑, (, ), {, }, [, ]}
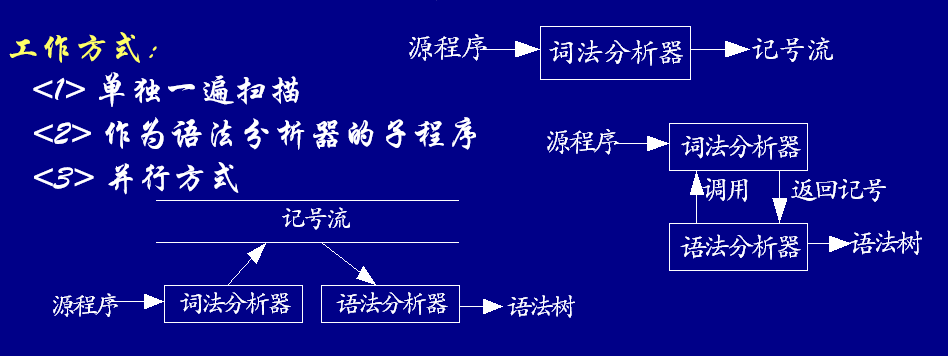
2.2 | 词法分析器的工作方式
输入: 源程序
输出: 记号流
2.3 | 正规式
定义:
定义2.2 令Σ是一个有限字母表,则Σ上的正规式r及其表示的集合L(r)递归定义如下:
ε和Φ都是Σ上的正规式,它表示集合L(ε)={ε}和Φ。
若a是Σ上的字符,则a是正规式,它表示集合L(a)={a}。
若正规式r和s分别表示集合L(r)和L(s),则
(a) r|s是正规式,表示集合L(r)∪L(s),
(b) rs是正规式,表示集合L(r)L(s),
(c) r是正规式,表示集合(L(r)),
(d)(r)是正规式,表示的集合仍然是L(r)。(加括弧改变优先级、结合性)
可用正规式描述的语言称为正规语言或正规集。
正规式可以严格的规定记号的模式, 用正规式说明记号的公式为: 记号 = 正规式, e.g. id=a(a|b)*
正规式的简化描述: 正闭包r+, 可缺省r?, 字符组[abc], 非字符组[^abc]
正规集: 能用正规式表示的集合
2.4 | 有限自动机
2.4.1 | 不确定的有限自动机NFA
定义:
NFA由五元组(S,∑, move, s0, F)表示
其中:
S是有限个状态的集合Σ是有限个输入字符的集合move是一个状态转移关系s0是唯一的初态F是终态集
NFA的特点: 不确定性, 即在当前状态下对于同一个字符有不同的状态转移(move是一对多的)
2.4.2 | 确定的有限自动机DFA
DFA 是 NFA 的一个特例,其中:
- 没有状态具有 ε 状态转移, 即状态转换图中没有标记 ε 的边
- 对每个状态 s 和每个字符 a 最多有一个下一状态 。
2.5 | 从正规式构造词法分析器(重点)
步骤如下:
(1)用正规式对模式进行描述;
(2)为每一个正规式构造NFA;
(3)将构造出的NFA转换成等价的DFA,这一过程也被成为确定化;
(4)把DFA化为最简形式,这一过程也被成为最小化;
(5)从简化后的DFA构造词法分析器。
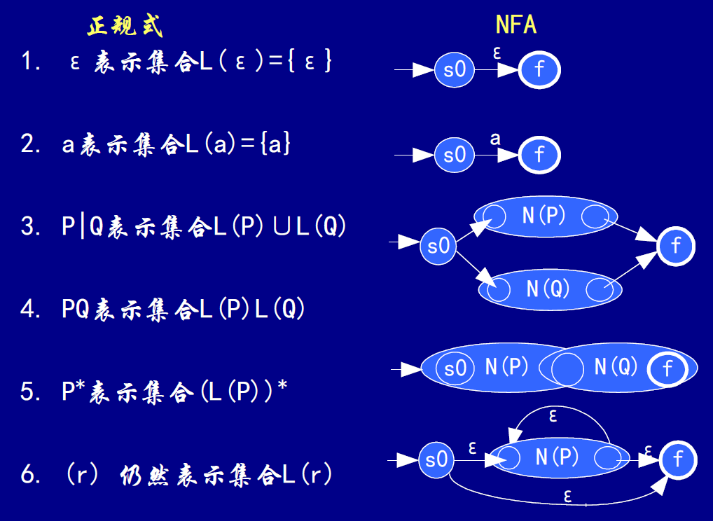
2.5.1 | 正规式构造NFA(Thompson 算法)
按如下关系将正规式转化为NFA:
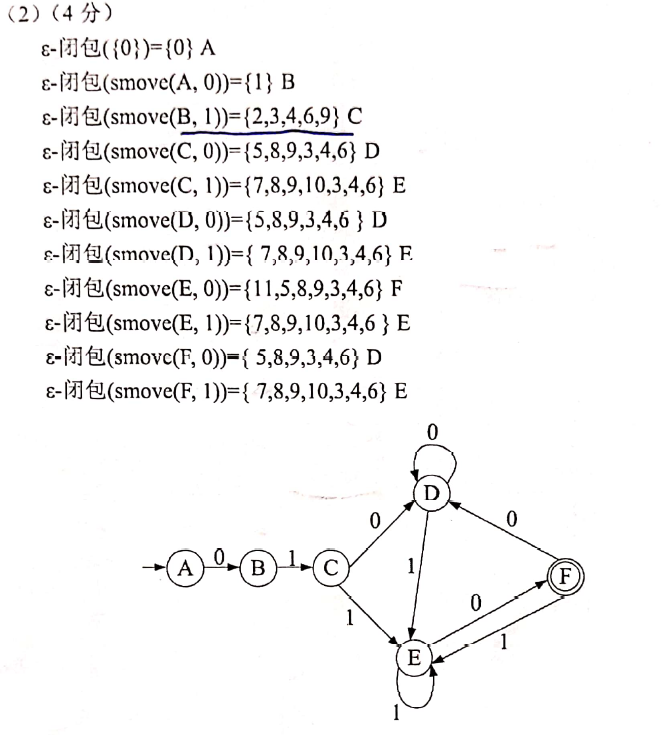
2.5.2 | 将构造出的NFA转换成等价的DFA(确定化)
不断求ε-闭包(smove(T, a));
其中:
ε-闭包(I)表示从状态I出发, 不经任何字符到达的状态全体smove(T, a)表示从状态S出发, 标记为a的下一状态全体
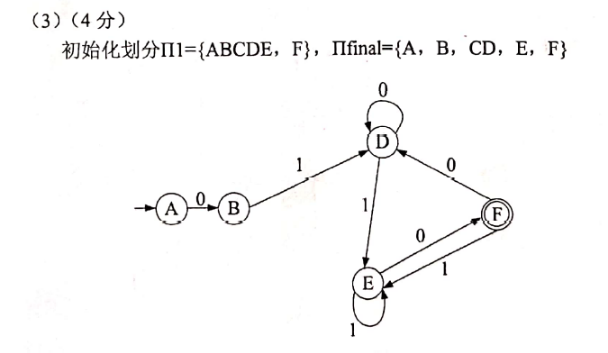
2.5.3 | 最小化DFA
先将状态集划分为终态和非终态
利用可区分的概念, 反复划分集合, 直到不能再分裂
3 | 题目
考试真题(填空):
符号表管理和出错处理是编译程序各阶段都涉及到的工作- 在编译器过程中, 实现语言关键字大小写不敏感的阶段是
词法分析, 分析语言结构的阶段是语法分析 - 不确定有限自动机中的有限是指
状态的数量是有限的 - Lex和Yacc是用于生成
词法分析器和语法分析器的工具 - 描述含010的01串的正规式是
(0|1)*010(0|1)* - 词法分析器的输入是
源程序, 输出是识别的记号流
考试真题(简答):
- 为什么在一般情况下用正规式而不用CFG来描述语言的词法?
答:
- 词法规则简单, 用正规式描述已足够
- 正规式的表示比CFG更直观, 简洁, 易于理解
- 有限自动机的构造比下推自动机简单, 且分析效率高
- 区分词法和语法, 为编译器的前端模块的划分提供方便
- 解释什么是编译器的扫描遍数
答:
编译器工作的每个阶段对以某种形式表示的程序进行一遍分析, 每个阶段将程序完整分析一遍的工作模式称为一边扫描
- 简述DFA和NFA有何区别
答:
DFA与NFA的区别表现为两个方面:一是NFA可以有ε转移,而DFA没有有ε转移。另一方面,DFA的状态转移move是从S×∑到S,而NFA的状态转移是从S×∑到S的幂集,即move将产生一个状态集合(可能为空集),而不是单个状态。
考试真题(计算):
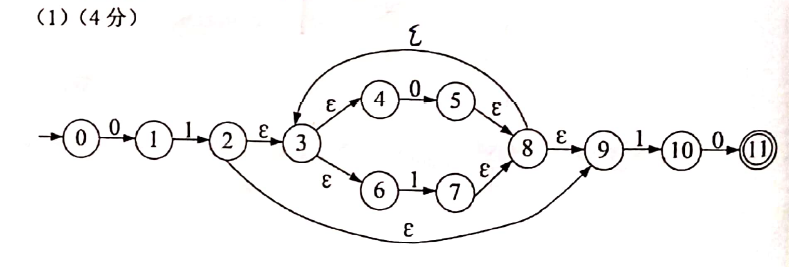
- 已知正规式
01(0|1)*10描述的正规集, 试给出:- 识别该正规集的NFA
- 识别该正规集的DFA
- 最小化的DFA
答: