论文阅读: Optimizing Dynamic Neural Networks with Brainstorm
本文最后更新于:2024年4月24日 晚上
Optimizing Dynamic Neural Networks with Brainstorm
- OSDI 2023
- presentation: https://www.youtube.com/watch?v=qBPBQ495YP4&t=2s
- 开源 github: https://github.com/Raphael-Hao/brainstorm
摘要
Dynamic neural networks (NNs), which can adapt sparsely activated sub-networks to inputs during inference, have shown significant advantages over static ones in terms of accuracy, computational efficiency, and adaptiveness. However, exist- ing deep learning frameworks and compilers mainly focus on optimizing static NNs with deterministic execution, missing optimization opportunities brought by non-uniform distribu- tion of activation in dynamic NNs. The key to optimizing dynamic NNs is the traceability of how data are dynamically dispatched to different paths at inference. Such dynamism often happens at sub-tensor level (e.g., conditional dispatching tokens of a tensor), thus hard for existing tensor-centric frameworks to trace due to misaligned expression granularity.
In this paper, we present Brainstorm, a deep learning frame- work for optimizing dynamic NNs, which bridges the gap by unifying how dynamism should be expressed. Brainstorm proposes (1) Cell, the key data abstraction that lets model de- velopers express the data granularity where dynamism exists, and (2) Router, a unified interface to let model developers express how Cells should be dynamically dispatched. Brain- storm handles efficient execution of routing actions. This design allows Brainstorm to collect profiles of fine-grained dataflow at the correct granularity. The traceability further opens up a new space of dynamic optimization for dynamic NNs to specialize their execution to the runtime dynamism distribution. Extensive evaluations show Brainstorm brings up to 11.7× speedup (3.29× on average) or leads to 42% less memory consumption for popular dynamic neural networks with the proposed dynamic optimizations.
- 目前的深度学习框架和编译器主要侧重于优化具有确定性执行的 静态神经网络
- 优化 动态神经网络 的关键主要是在推理时数据如何动态分配到不同路径的 可追溯性
- 由于动态通常发生在 sub-tensor 级别, 现有的框架难以跟踪
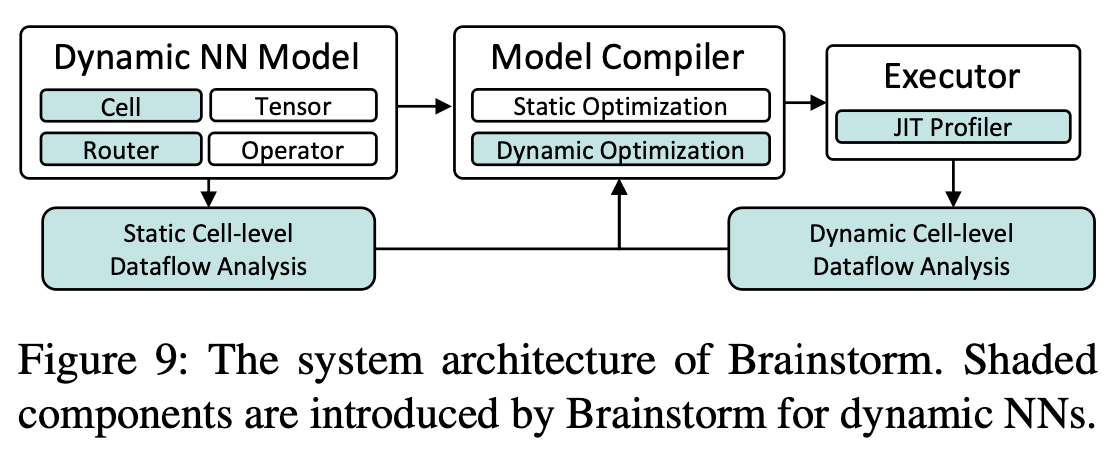
- 本文提出了 Brainstorm, 一个用于优化动态神经网络的深度学习框架, 通过统一的动态表达方式来弥补这个差距
- Brainstorm 主要提出了两个概念:
- cell: 关键的数据抽象, 用于让模型的开发者表达动态存在的数据的粒度
- router: 一个统一接口, 让模型开发者能表达如何动态调度 cell
Introduction & background
三种不同的 Dynamic NN 模式:
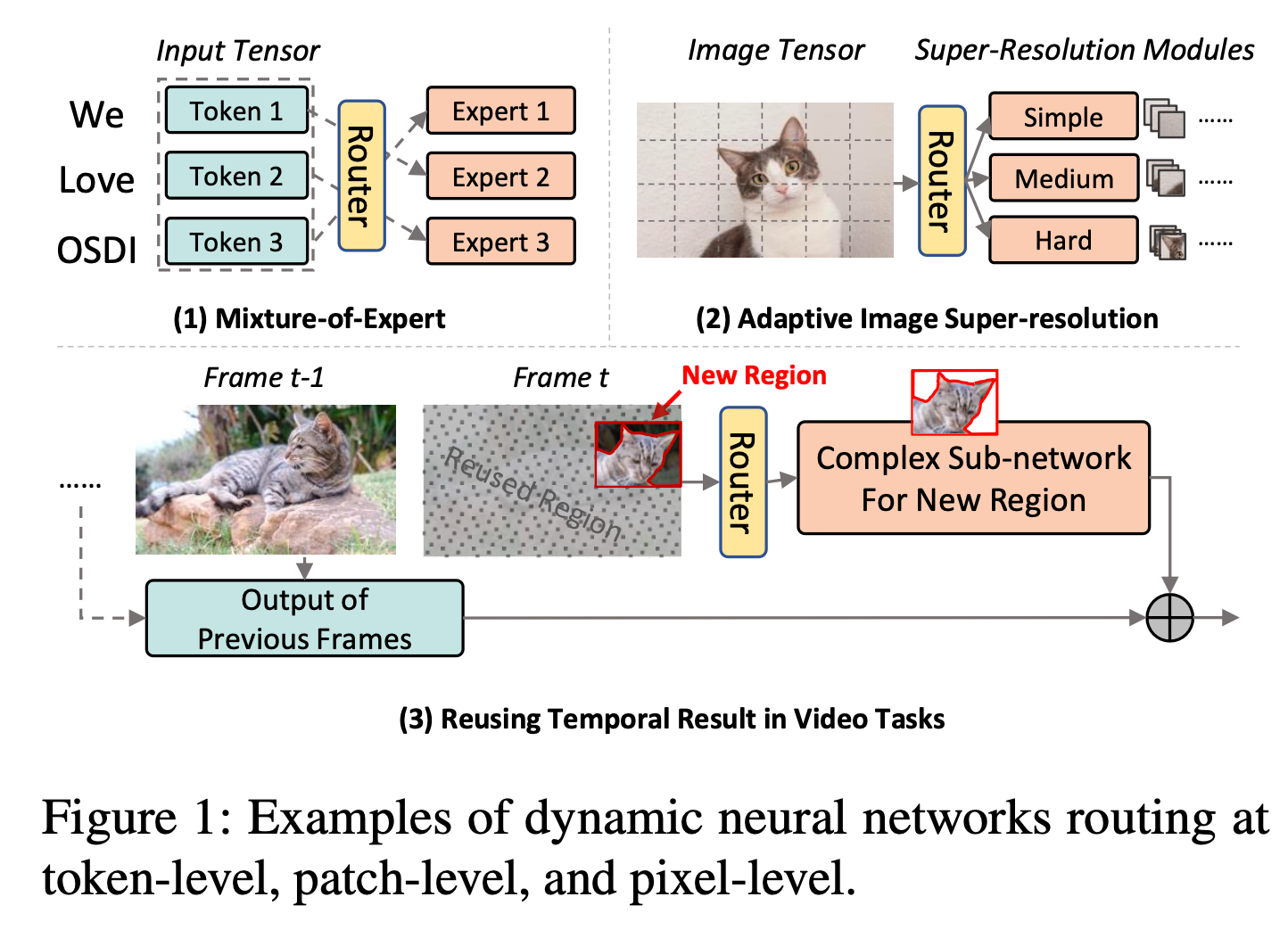
- 对输入 token 的 route
- 根据超分辨率的难度将图像 patch 到不同的分支
- route new pixels to computation and skips duplicated pixels of previous frames
一些优化动态网络的机会
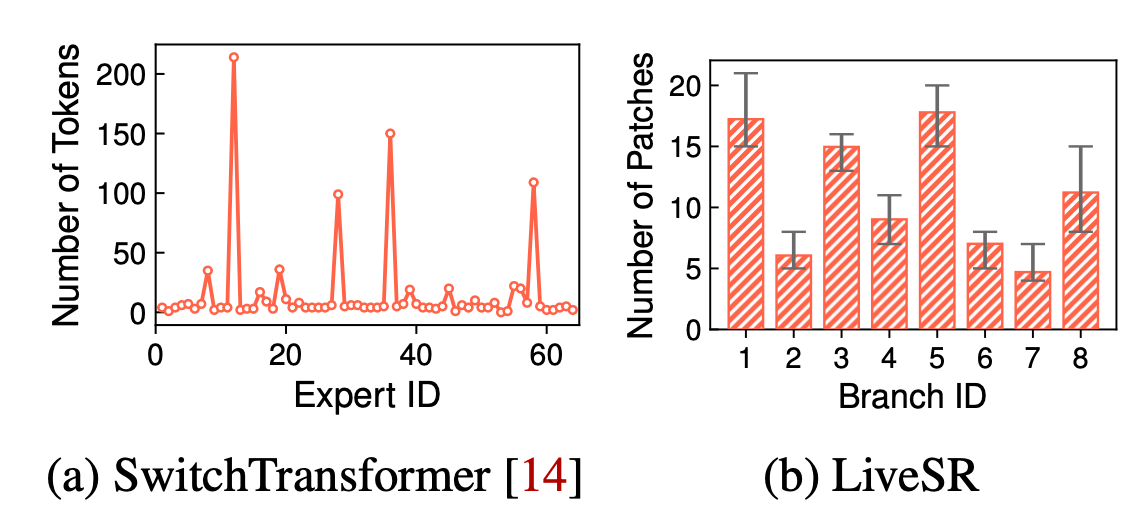
上图的 (a), (b) 显示了在两个动态网络中 token / patch 被分配到不同的 expert / branch 的情况, 图中显示这种分配是不均匀的, 可以通过调整分配策略来高效的利用计算资源
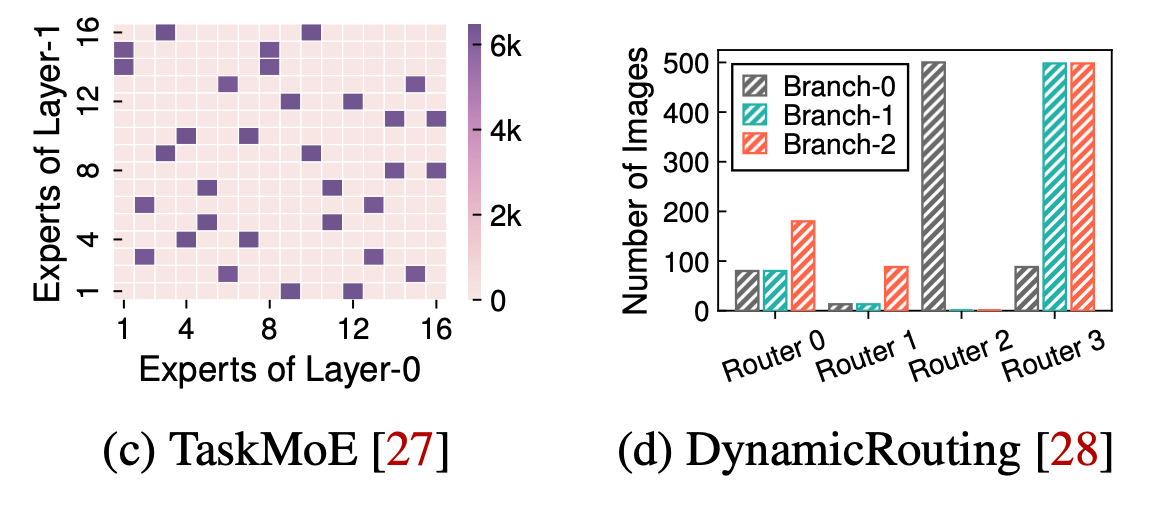
图 © 显示了一个 MoE 网络的多层相关性, 文中发现两个连续层的分支激活具有相关性, 可以在同一 GPU 上共置专家 (co-locating experts) 来节省 GPU 通信
图 (d) 显示了 DynamicRouting 中选定 router 的分支激活, 其中有 186 个经过训练的路由器, 可以将图像转发到三个分支中的 1-2 个分支, 然而文中发现许多 router 具有偏向分布, 如图所示
优化上述动态神经网络的机会主要是能够以动态发生的粒度来收集和统计
因此本文的 brainstorm 提出了一种原则性设计: 让模型开发人员公开需要跟踪的信息, 并利用收集到配置文件进行动态优化
核心数据抽象: Cell 和 Router
Cell
为了让模型开发者定义动态发生的数据粒度, brainstorm 使用 cell 这个数据抽象对传统的 tensor 进行增强, cell 是多个 branch 之间动态调度的单位, 模型开发人员可以使用:
1 | |
这个 API 对任何 tensor 进行注释
Router
同时为了动态调度 Cell, Brainstorm 引入了统一的 Router API, 可以支持通过 router_fn 来决定 cell 在多个分支之间的动态放置:
1 | |
使用 cell 和 router 进行动态调度的例子:
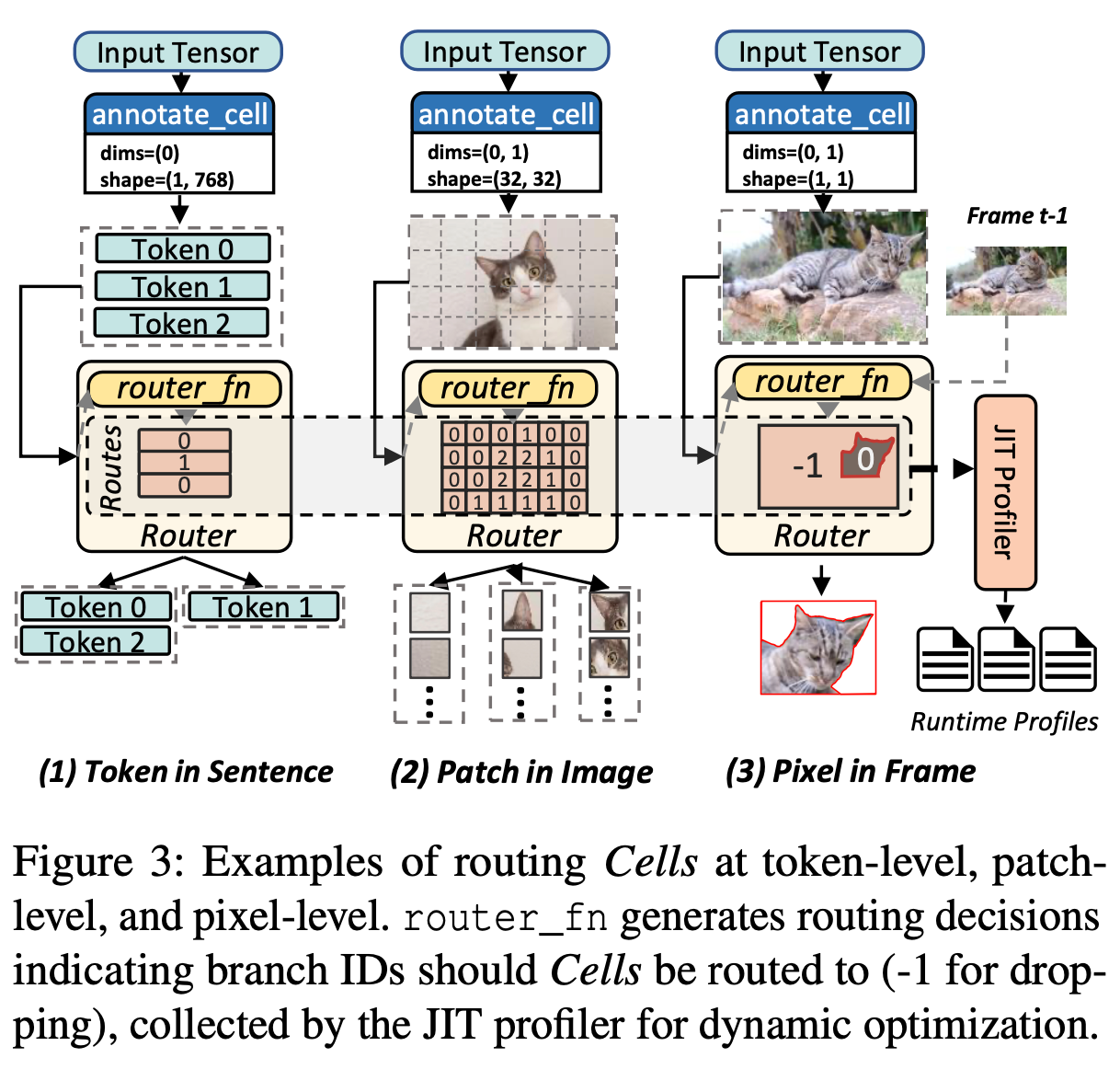
通过 cell 和 router 可以实现多种优化, 文章主要介绍了如下几种, 以及这些优化所需的信息:
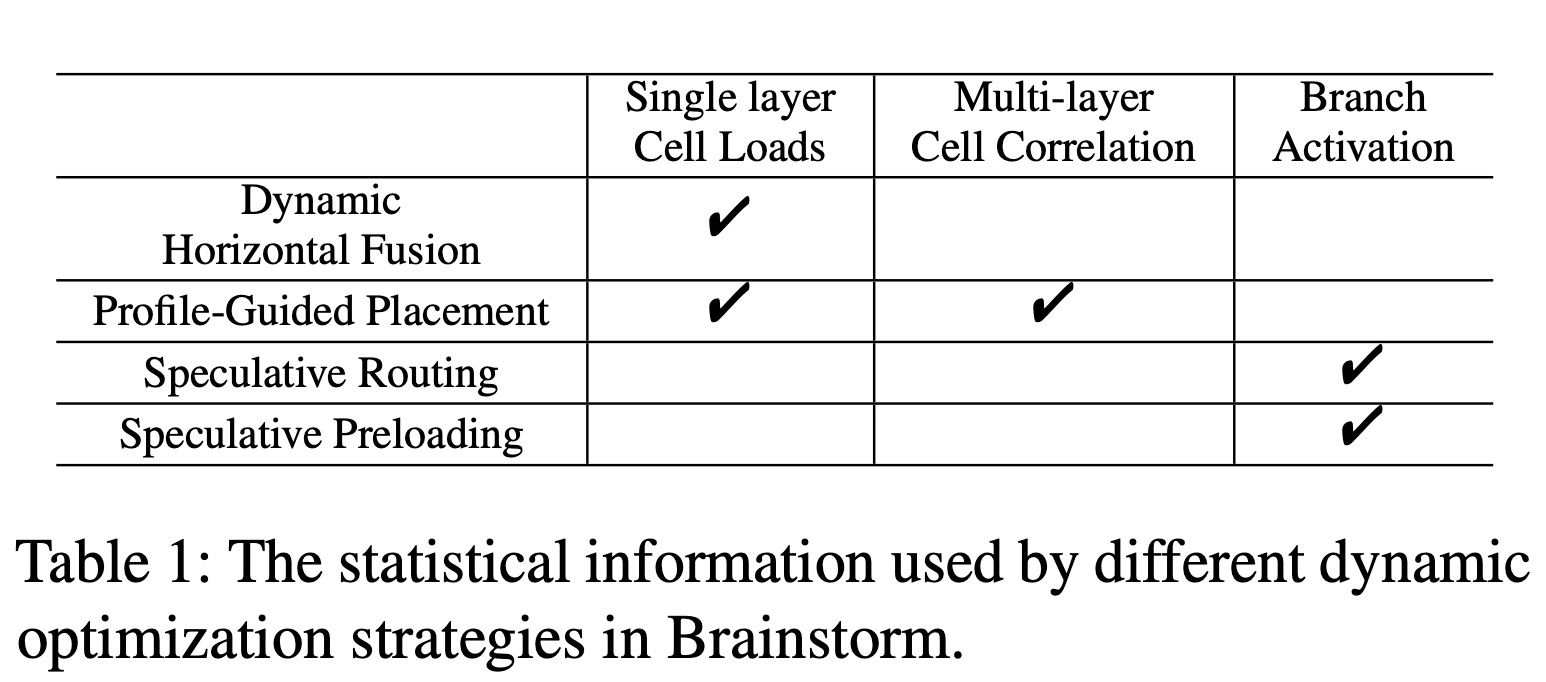
动态优化策略 Dynamic Optimizations
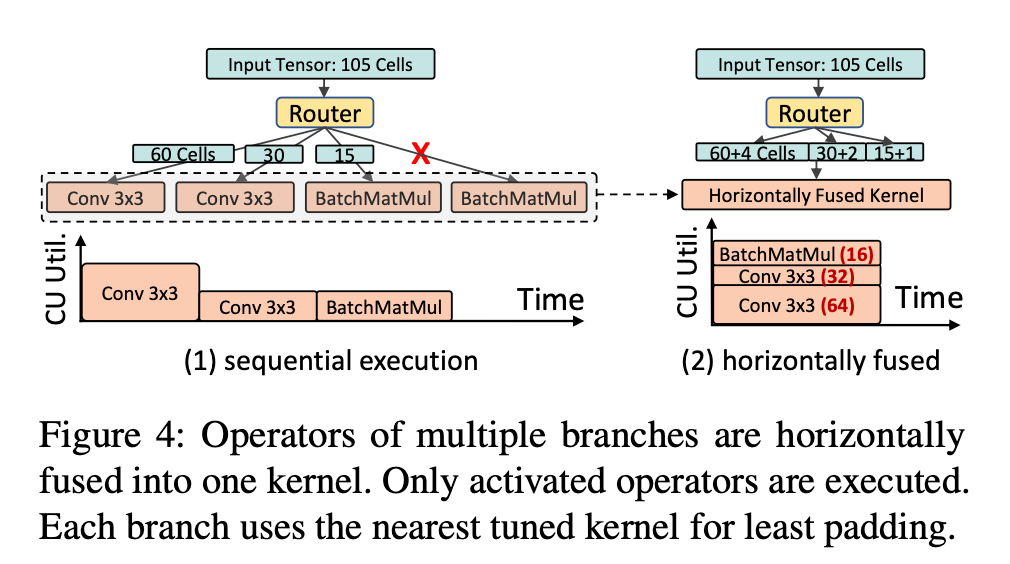
Dynamic Horizontal Fusion
Horizontal Fusion (水平融合) 是一种编译优化, 可以讲模型的并发分支融合进入融合运算符中, 以提高 GPU 的利用率并减少启动开销
现有的水平融合方法不能用于动态 DNN, 因为它们假设的是一个静态数据流图, 其分支全部由相同的输入激活 (==没太看懂什么意思==)
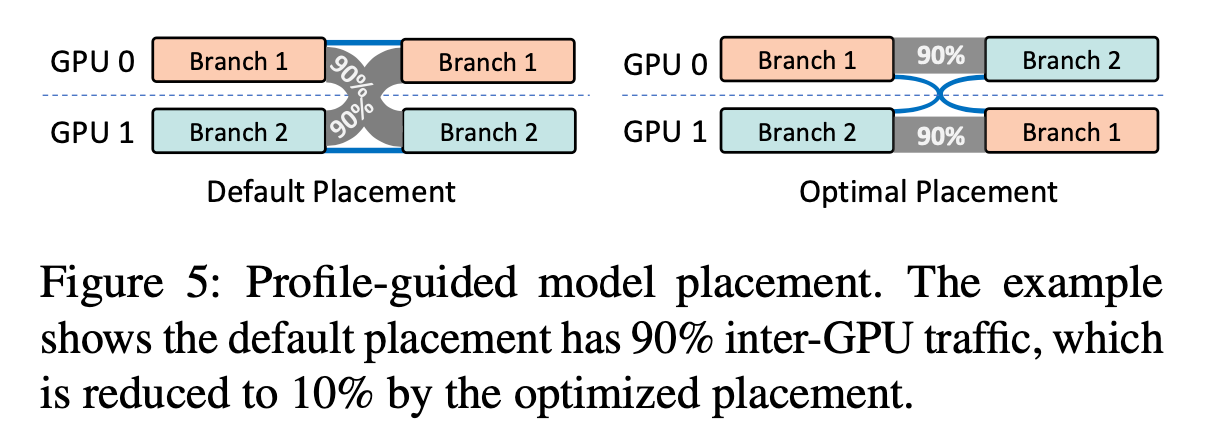
Profile-Guided Model Placement
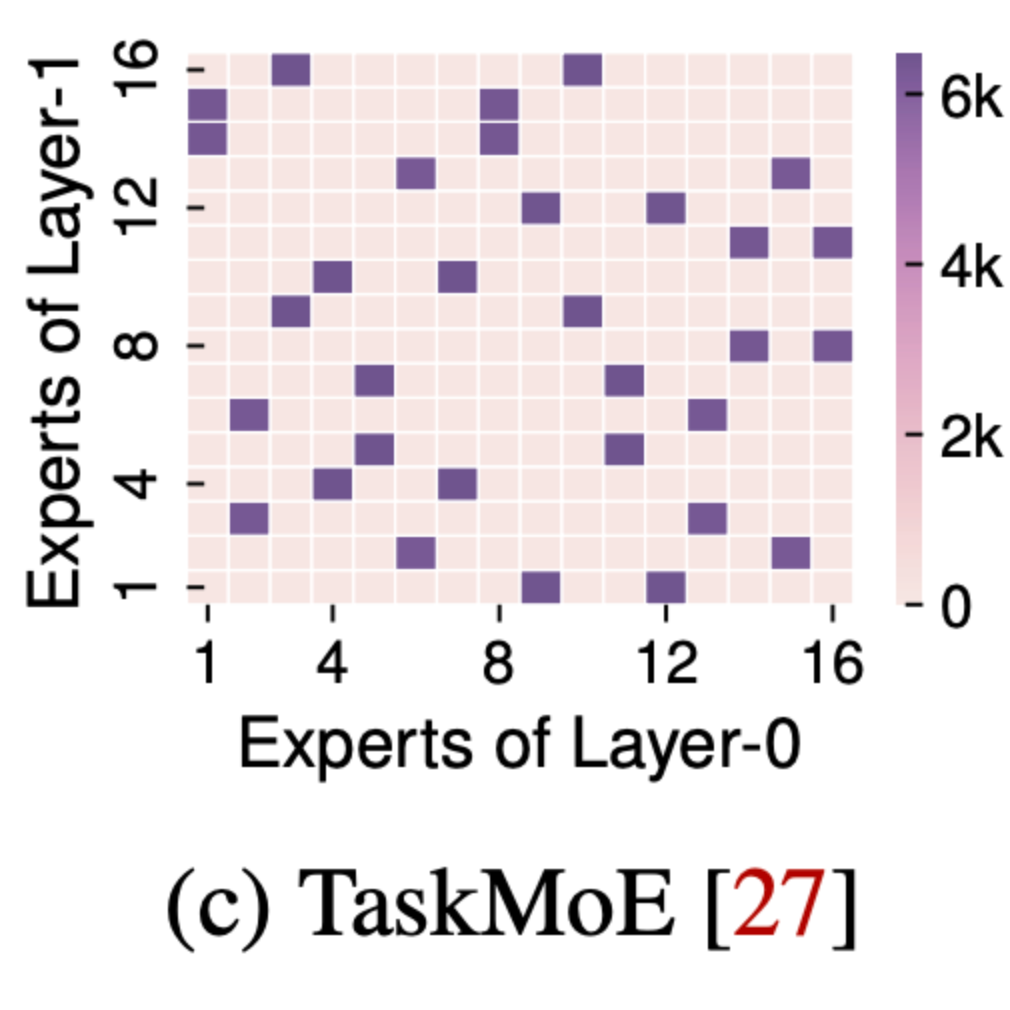
如图 c 所示, 两个 expert 同时被激活的概率很高, 这些高度相关的 experts 之间的通信较多, 因此可以将相关的子网络共置在同一个 GPU 上, 以减少 GPU 之间的通信
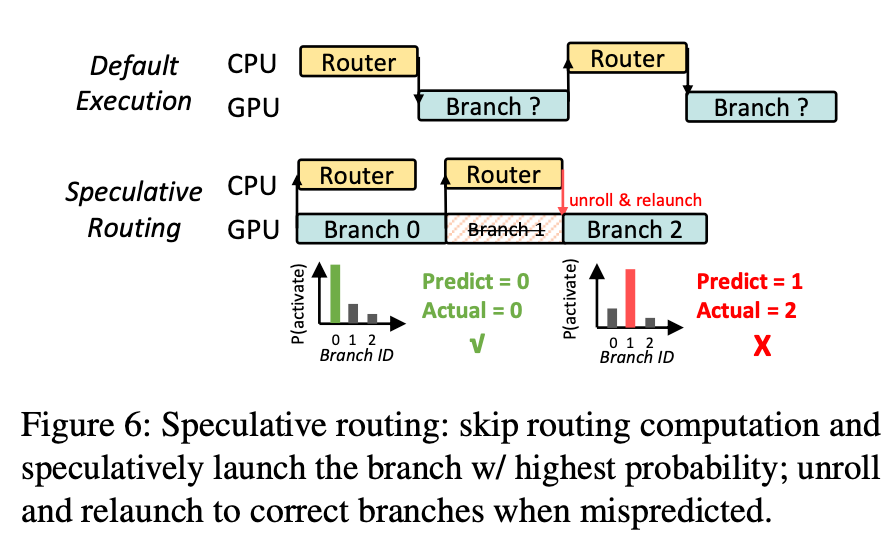
Speculative Routing
Speculative Routing (投机路由), 基于分支路由的高度可预测性, 可以投机的跳过 router_fn 的执行来隐藏开销, 当错误预测时再重新执行分支
Speculative Weight Preloading
为了在有限的 GPU 内存上运行大型模型的推理, 通常需要在 GPU 内存和 CPU 内存之间交换层的 weights 以减少 GPU 的内存需求, 为了隐藏内存迁移的延迟, 现有的解决方案需要知道各层的执行顺序, 以便在以流水线方式执行前面的层时预加载必要的权重, 但是动态神经网络没有确定的层执行顺序, 动态激活的分支只有在做出路由决策的时候才能知道
和 speculative routing 相似, 本文采用分支激活的统计分布来进行 weight 的预加载, 当预测失败的时候重新执行分支
跟踪 Cell-level 的数据流
为了实现之前所说的动态优化策略, 最重要的是判断 cell 是如何沿着网络传输的, 在动态 NN 中, 有两种类型的单元级数据流:
- static dataflow: 绝大多数静态算子, 比如
Conv2D - dyanmic dataflow: 由
Router在运行时确定的数据流
前者是为了确定 cell 在静态层之间的关系; 后者是为了确定 cell 是如何在分支之间被路由的.
static cell-level dataflow
Tensor-centric dataflow graphs only preserve relations be- tween tensors without the information of Cells. To trace all possible Cell-level dataflow of static operators, Brainstorm uses symbolic execution at Cell-level to extract finer-grained relations in ahead-of-time compiling.
为了追踪 cell-level 的信息, brainstorm 采用了符号执行 (symbolic execution) 来在编译前提取更加细粒度的信息
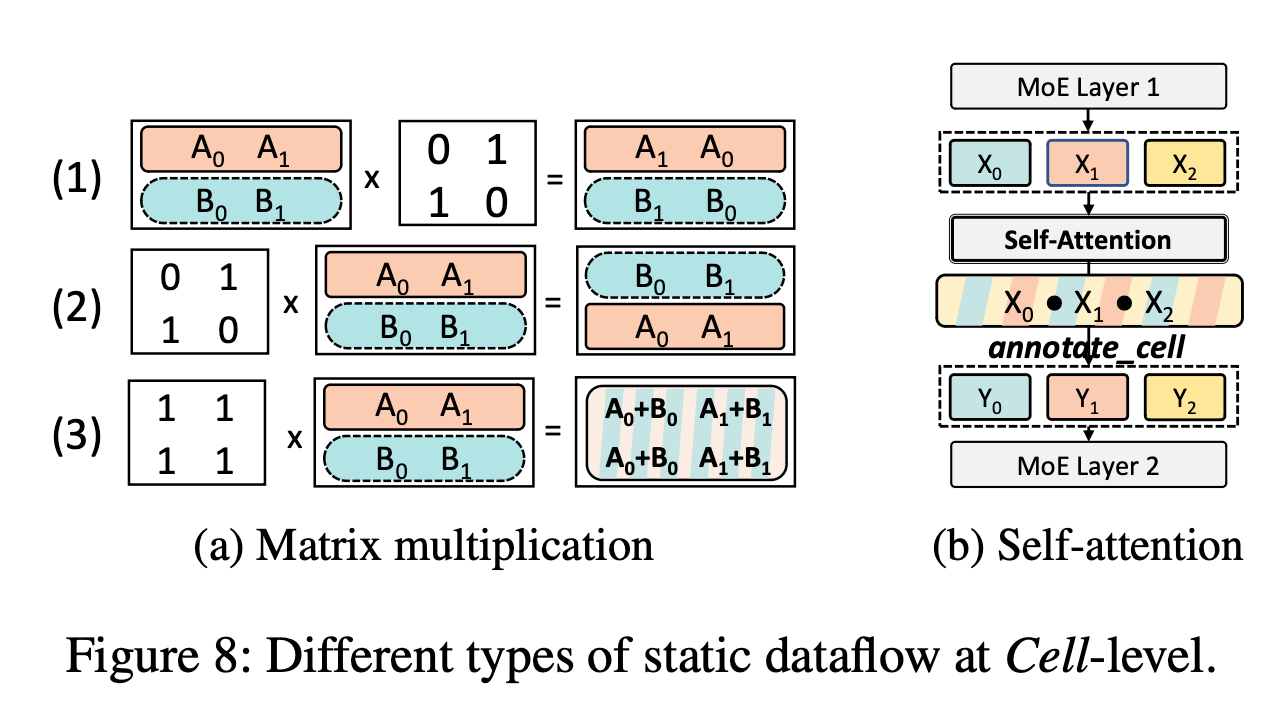
Figure 8(a) 展示了几种包含多个 cell 的 tensor 的乘法示例, 其中 A 和 B 表示 cell:
- The first preserves cell positions
- The second reorders cells
- The third mixes all cells in the output
Figure 8(b) 展示了两个 MoE 层之间的自注意力算子的静态 cell 级数据流, ==这里也没太看懂==
dynamic cell-level dataflow
路由策略由开发者在 router_fn 中指定 , Brainstorm 只收集路由决策的统计概况, 而不关心他们的生成方式
如果 Cell-level 的分析策略被启用, 每次调用 Router 时, brainstorm 将 routing decision 收集到一个 buffer 中, brainstorm 设计了一个单独的线程将缓冲区流式传输到配置文件
Implementation
braintstorm 基于 pytorch, 13000 line of code:
- 3000 lines: brainstorm core abstraction
- 3000 lines: dynamic optimizations
- 3000 lines: c++ code for kernel scheduling & sparse cell communication
- 1500 lines: 1500 lines for auto-transformation
相关概念
MoE (mixture-of-expert)
MoE(Mixture of Experts) 是一种将多个神经网络专家组合起来进行训练和预测的方法。其主要思想是:
- 将输入数据分配给不同的专家网络。通常使用一个 门控网络 来学习如何将数据分配给不同的专家。
- 每个专家网络只专注于处理部分数据,从而整体模型能够 Capture 更多的distribution modes。
- 在预测时,将输入同时提供给每个专家网络,由门控网络合并每个专家的预测得到最终结果。
- 通过端到端的训练,门控网络和专家网络都能够协同优化。