论文略读: Nimble
本文最后更新于:2023年11月2日 下午
Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning
resource
- 会议: NeurIPS
- 开源代码: https://github.com/snuspl/nimble
摘要
- 提出了 AoT (Ahead-of-Time 调度), 即在执行 GPU kernel 之前进行程序调度
- 提出了并行执行 GPU tasks (通过在单 GPU 中利用多 streams)
目前已知的多种 DL 框架:
- Caffe2
- MXNet
- PyTorch
- TensorFlow
都提供了高层的 API, 用户可以直接描述训练和推理网络的过程而无须直接操作GPU, 然后深度学习框架会自动处理 GPU 上的复杂问题.
在 GPU 处理任务之前, DL 框架首先要经过一系列的准备工作 (GPU task scheduling), 然后将 task 提交给 GPU 来执行.
- 问题1: GPU 调度的时间不能忽视
本文注意到目前的 GPU task scheduling 是在 运行时 进行的, 例如,TensorFlow、Caffe2 和 MXNet 将神经网络表示为 DL 算子的计算图,并在满足算子的依赖关系后在运行时调度算子的 GPU 任务; 同时,对于 PyTorch 和 TensorFlow Eager (tensorflow 的命令式解释执行模式),GPU 任务是在运行时调度的,因为 Python 代码是逐行解释的。
本文的发现: 当神经网络的训练和推理由很多小而短的 GPU 任务组成时, GPU 调度的开销就不能忽略不计, 并且会对效率产生很大的影响
- 问题2: GPU 任务过于串行而忽略了并行执行的机会
利用运算符间并行性可以提高执行此类神经网络的性能,尤其是在推理的情况下。 然而,现有的深度学习框架的设计和优化是为了安排 GPU 任务一次执行一个,因此很难利用运算符间的并行性。
Nimble 构建在 pytorch 上, 用户可以通过将 DL 模型实例包装在 Nimble 对象中,将 Nimble 无缝应用到他们的 PyTorch 程序中。
一些背景知识
DL 框架和 GPU Task Scheduling (两类深度学习框架)
包括 TensorFlow, Caffe2 和 TorchScript 在内的一些深度学习框架将神经网络表示为计算图, 每个节点代表一个深度学习运算符, 每条边表示两个运算符之间的依赖关系, 这样的框架的运行时主要由两部分组成: (都是c++写的)
- operator emitter
- worker
包括 Pytorch 和 TensorFlow Eager 将神经网络表示为一个 python 程序, 在这类框架中没有计算图和 operator emitter, 而是根据 python 解释器在逐行执行时发出 operator, 因此, 第二类深度学习框架还通过 python interpreter 和 worker 来进行运行时调度.
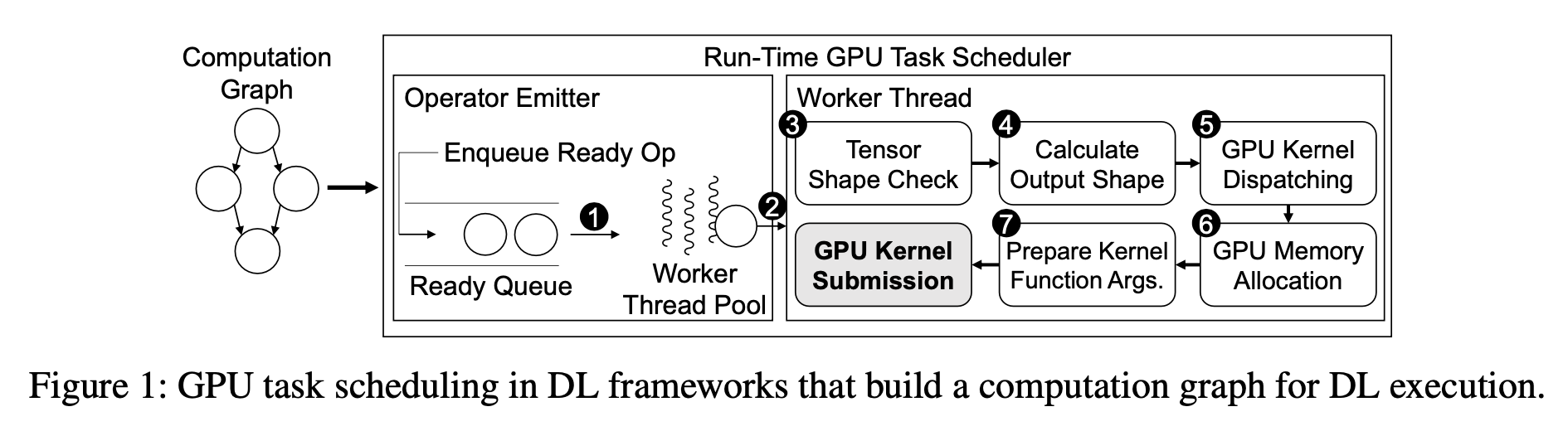
Figure1 展示了 TensorFlow 和 Caffe2 这类框架是如何进行 GPU 任务调度的
GPU Streams
A GPU stream is a queue of GPU tasks where the tasks are scheduled sequentially in FIFO order.
同一个流上的 kernel 不能并行执行, 但是多个流上的 kernel 可以并行计算, 占用 GPU 资源的不同部分, 但是除非由流同步原语明确指定, 否则无法保证他们之间的执行顺序
但是目前的深度学习框架通常只使用一个 GPU stream
Note that existing DL frameworks are designed and optimized to submit GPU kernels to a single GPU stream. For example, TensorFlow uses a single compute stream per GPU for running its kernels.
一些实验和动机
过高的调度开销
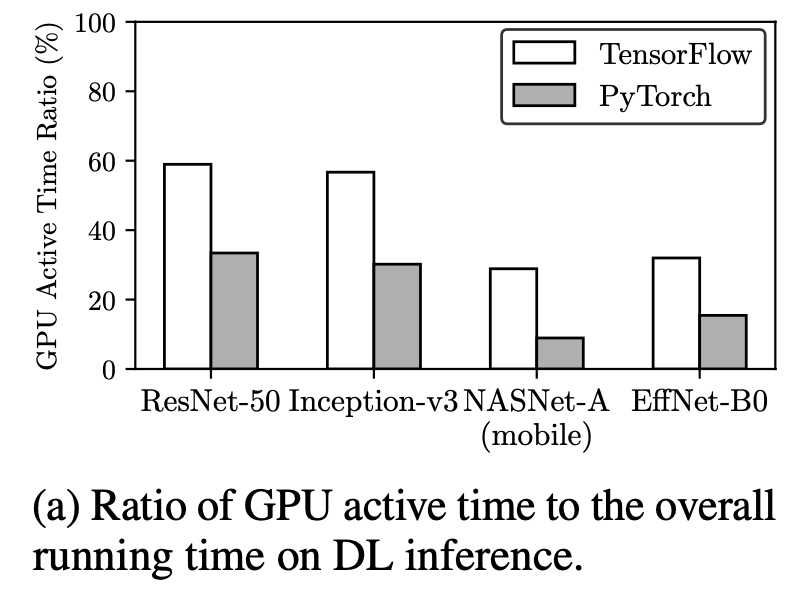
上图显示了 tensorflow 和 pytorch 的 GPU 运行时间占比, python 的低效率归咎于慢速的 python interpreter, 但是即使是 C++ 这样低开销的语言, GPU 仍然有很大一部分的空闲时间, 这可能就是运行时调度引起的问题
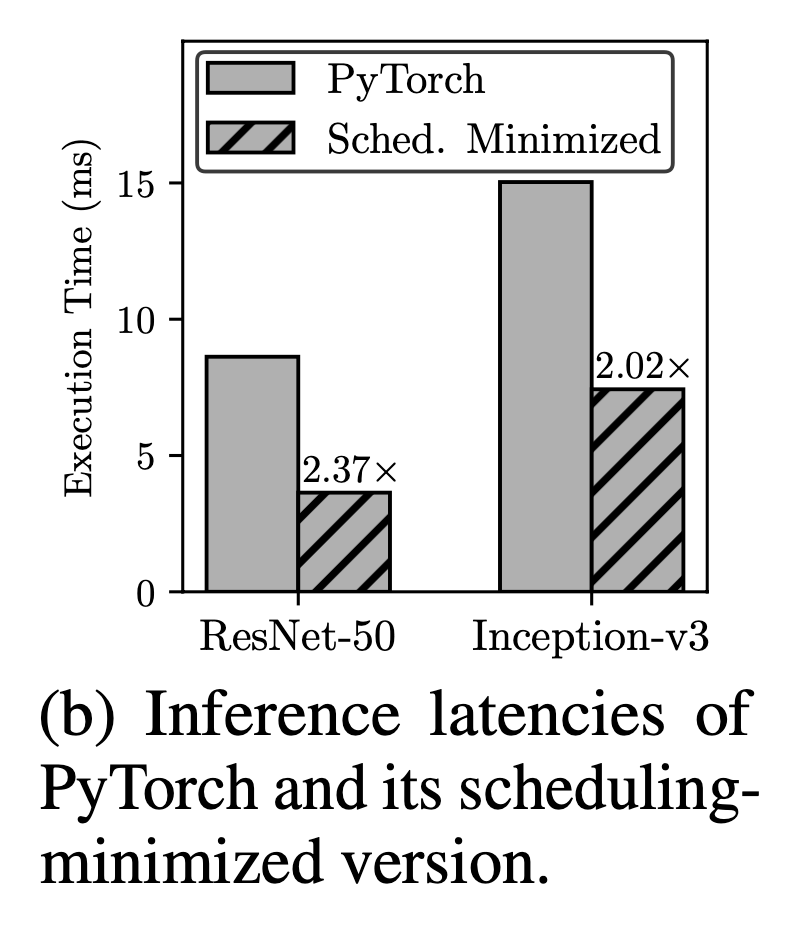
上图展示了对 “GPU调度时间” 的分析, 本文做了一个实验, 忽略了在运行时之前完成的所有冗余的程序 (Figure2 中的 3, 4, 5, 6), 然后直接将程序提交给 GPU 内核而无须调度, 这时结果如上图所示, 获得了 2 倍以上的加速
非并行的任务执行
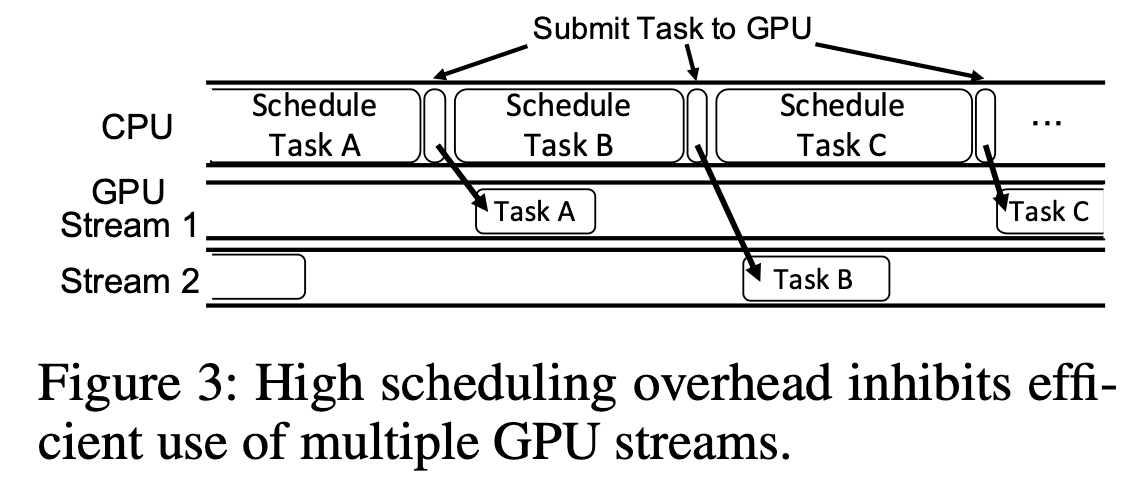
上图显示了 GPU 调度的开销导致了 GPU 的 “伪并行”
system design
AoT Scheduling
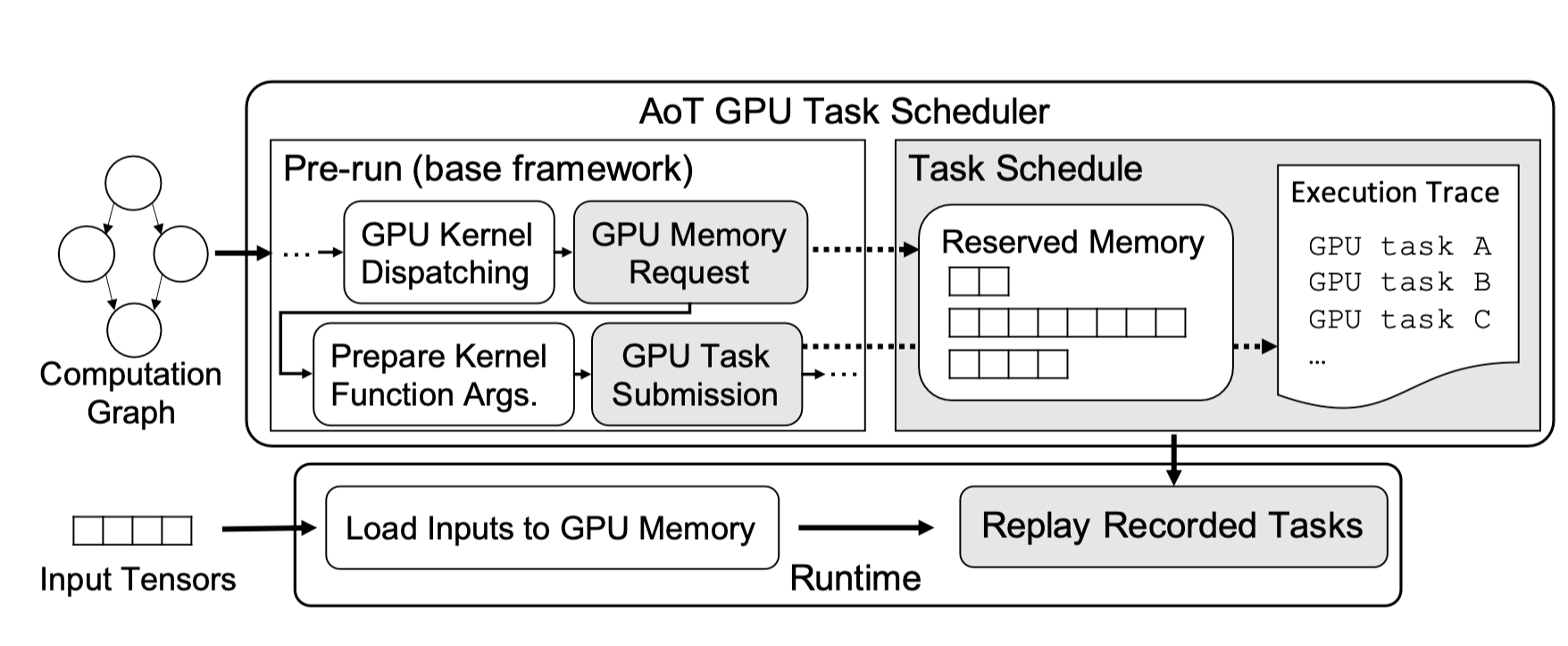
通过预执行的方式收集信息, 预执行是对训练/推理网络的单次迭代, 在执行过程中拦截信息:
- invocations of GPU tasks (GPU 任务调用)
- allocation of GPU memory (GPU 内存分配)
如何收集这些信息:
we use CUDA stream capture APIs for capturing information of GPU tasks issued on CUDA streams
如何利用这些信息:
instantiate a CUDA Graph, a feature introduced in CUDA 10, (i.e., execution trace representation in Nimble) from the captured information.
Stream Assignment Algorithm
例如如果三个 GPU 任务 A, B, C, 并且 C 任务依赖 A 和 B 的输出, 在非并发(单个流)的情况下可以以 A-B-C 或者 B-A-C 的顺序执行, 但是如果在并发情况下就需要流之间的同步来保证 A 和 B 在 C 之前执行完成
在 CUDA 中, 实现这种不同流之间的依赖关系可以利用 events , 为 A 和 B 分别创建一个 event, 然后 C 调用 cudaStreamWaitEvent 来进行等待
Nimble 提供的多 stream 并行对于用户来说是透明的, 但是当运行具有可并行结构的神经网络时会加快速度
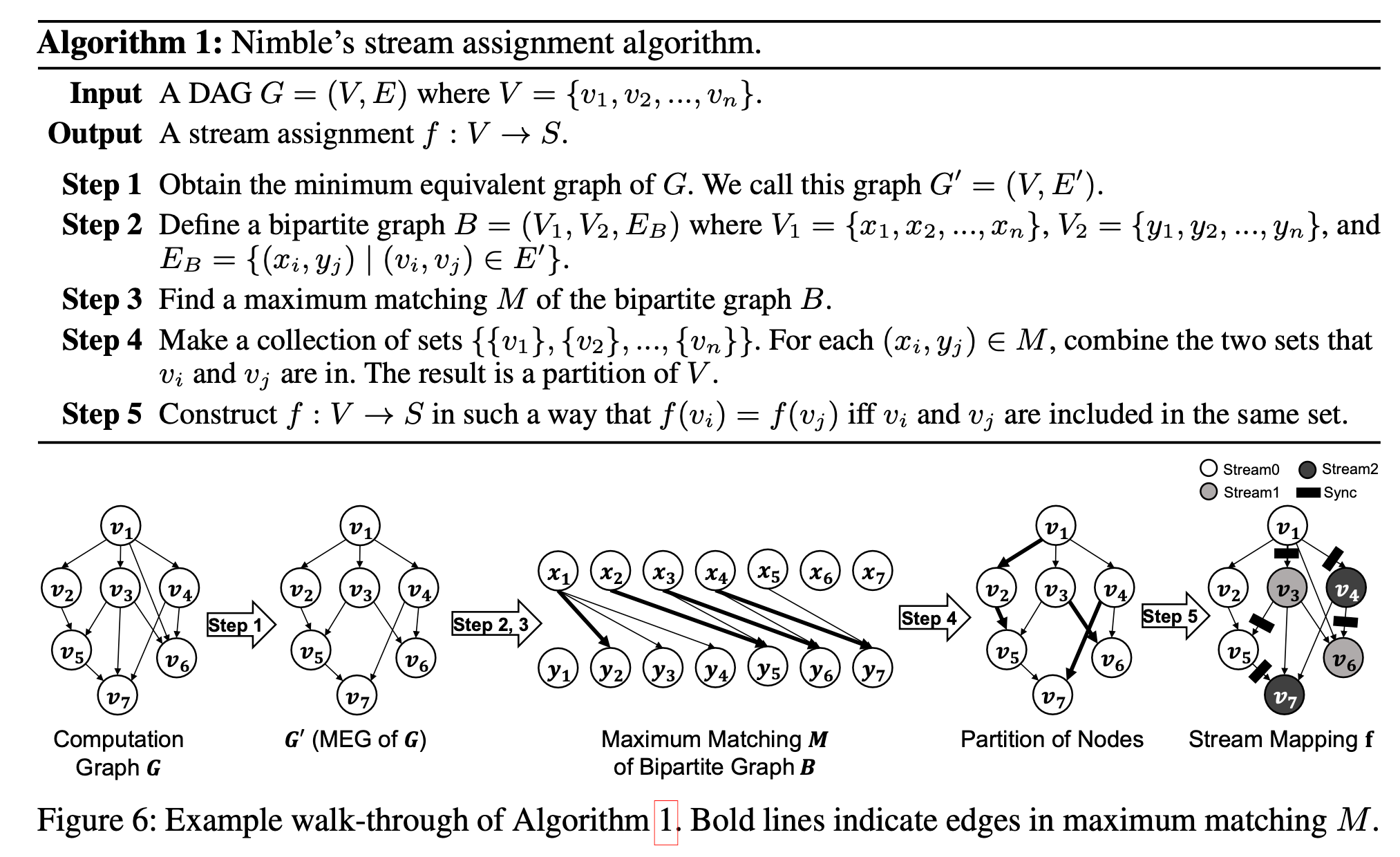
整体的 stream 分配和 同步 分配算法如上所示
Evaluation
setup:
We implement Nimble on PyTorch v1.4 with CUDA 10.2 and cuDNN 8.0.2.
For evaluation, we use an NVIDIA V100 GPU along with 2.10GHz Intel Xeon CPU E5-2695 v4.
指标:
- Inference Latency

- Impact of Multi-stream Execution
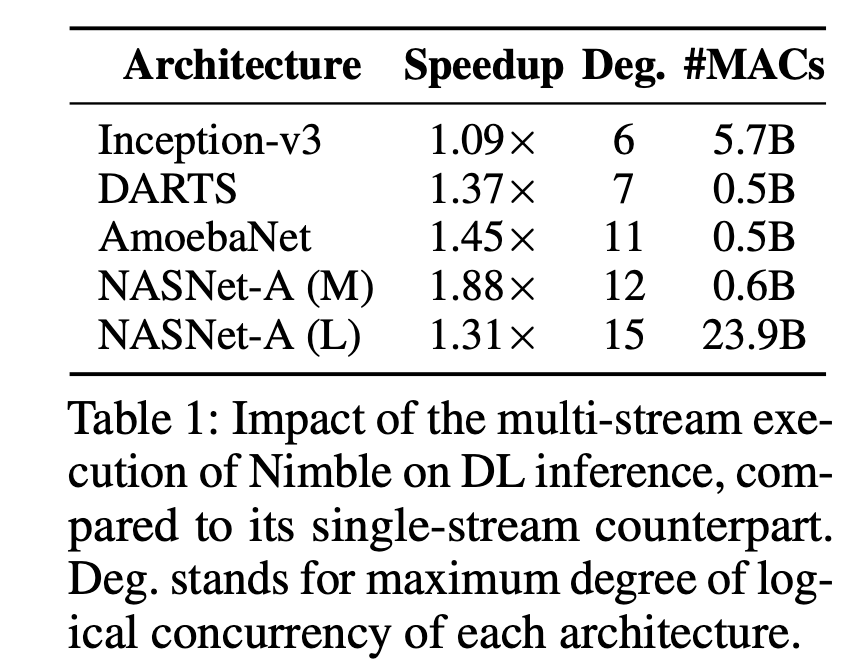
Table 1 显示了 multi-stream 相比 single-stream 的优化加速
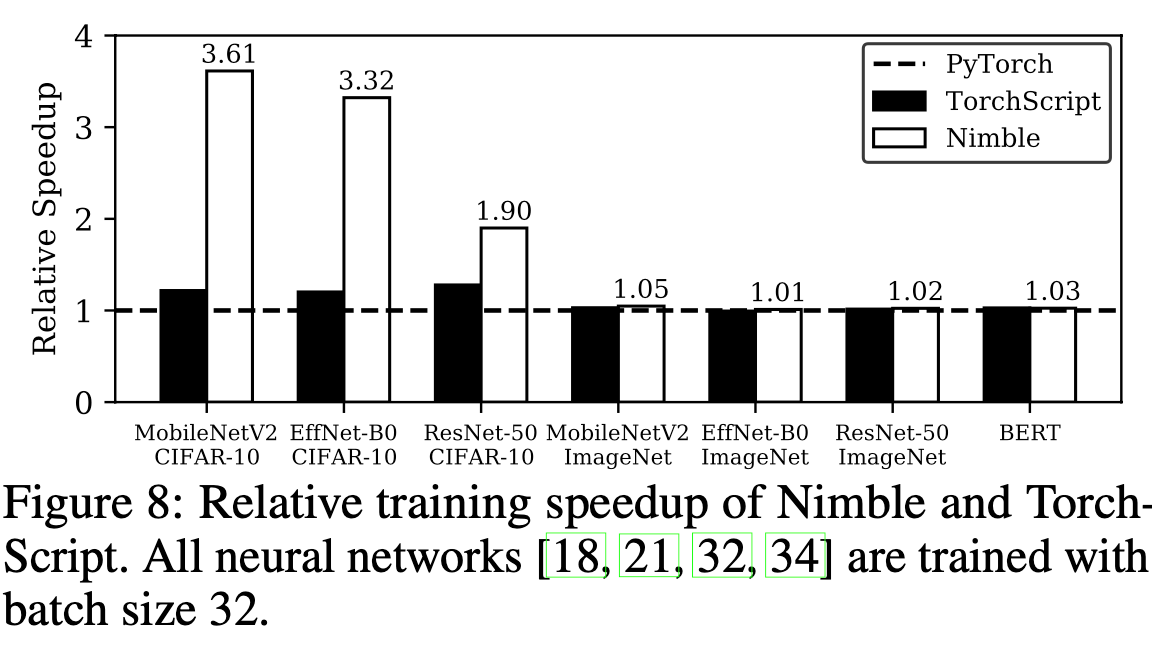
- Training Throughput