论文略读: MuxFlow
本文最后更新于:2023年11月2日 下午
MuxFlow: Efficient and Safe GPU Sharing in Large-Scale Production Deep Learning Clusters
- 北京大学 & 字节, arxiv 预印
摘要
Large-scale GPU clusters are widely-used to speed up both latency-critical (online) and best-effort (offline) deep learning (DL) workloads. However, most DL clusters either dedicate each GPU to one workload or share workloads in time, lead- ing to very low GPU resource utilization.
We present MuxFlow, the first production cluster system that supports efficient and safe space-sharing for DL workloads. NVIDIA MPS provides an opportunity to share multiple workloads in space on widely-deployed NVIDIA GPUs, but it cannot guarantee the performance and safety of online workloads. MuxFlow introduces a two-level protection mechanism for memory and computation to guarantee the performance of online workloads. Based on our practical error analysis, we design a mixed error-handling mecha- nism to guarantee the safety of online workloads. MuxFlow further proposes dynamic streaming multiprocessor (SM) allocation and matching-based scheduling to improve the efficiency of offline workloads. MuxFlow has been deployed at CompanyX’s clusters with more than 20,000 GPUs. The deployment results indicate that MuxFlow substantially im- proves the GPU utilization from 26% to 76%, SM activity from 16% to 33%, and GPU memory from 42% to 48%.
大规模GPU集群被广泛应用于加速具有 低延迟关键性(在线)和尽力而为性质(离线) 的深度学习工作负载。然而,大多数深度学习集群要么将每个GPU专门分配给一个工作负载,要么按时间共享工作负载,导致GPU资源利用率非常低。
我们提出了MuxFlow,这是第一个支持深度学习工作负载有效且安全空间共享的 生产集群 系统。NVIDIA MPS为广泛部署的NVIDIA GPU提供了空间共享多个工作负载的机会,但它无法保证在线工作负载的性能和安全性。MuxFlow 引入了 两级内存和计算保护机制, 以保证在线工作负载的性能。基于我们的实际错误分析,我们设计了一种混合错误处理机制来保证在线工作负载的安全性。MuxFlow进一步提出了 动态流 Multiprocessor(SM)分配和基于匹配的调度,以提高离线工作负载的效率。MuxFlow已经在CompanyX拥有超过2万个GPU的集群中进行了部署。部署结果表明,MuxFlow将GPU利用率从26%大幅提高到76%,SM活动从16%提高到33%,GPU内存从42%提高到48%。
总而言之,MuxFlow通过在GPU上并发安全高效地运行多个工作负载,极大地提高了数据中心集群中GPU资源的利用效率。
Background & Intro
- 提出了 在线工作负载(例如实时推荐, 机器翻译, 自动驾驶等) 和 离线工作负载(例如深度学习训练, 批量的推理, 科学计算等) 同时处理的问题
- 目前主要的企业方案:
- 设定 GPU 集群, 然后为在线工作负载保留特定的 GPU
- 目前主要的限制: 将单个GPU用于单个工作负载, 导致 GPU 无法得到充分的利用
- 优化的常见方案:
- 分时: 将时间片分配给不同的工作负载
- 空间共享
- 多进程服务 (MPS)
不同的 GPU 共享的方式

时间片共享无法完成真正的并行, 效率不高
空间共享主要有三种方式:
- 使用 NVIDIA 的 MIG(Multi-Instance GPU) 技术, 可以将 GPU 划分为多个 Instance, 但是这些划分的 Instance 无法在 workload 执行的时候动态调整, 并且 MIG 技术只在最新的部分 GPU 上提供 (A100, H100)
- 使用 CUDA 的 multiple streams, 可以执行来自多个 workload 的 kernel, 但是 NVIDIA 的 stream 只能在一个进程中和其他 stream 共享, 这使得利用 multiple streams 需要进行 workload 的合并, 而在生产集群中难以管理
- 使用 NVIDIA 的 MPS (Multi-Process Service), 可以做到将不同的 sm sets 分配给不同的 workload, 同时可以控制每个 workload 使用的 SM 的比例, 并且 MPS 被大多数 NVIDIA GPU 支持
MPS 带来的问题
性能(实时性保证)和错误的传播问题:
首先,生产集群的首要目标是保证在线工作负载的性能,例如实时推荐和机器翻译。 这些工作负载具有严格的延迟要求,因为较长的延迟可能会影响用户的体验。 但是,MPS 无法保证在线工作负载的性能。 其次,MPS存在严重的错误传播问题,即当一个工作负载遇到错误时,共享工作负载也可能受到影响。 保证共享工作负载的安全至关重要,尤其是生产集群中的在线工作负载。
MuxFlow 的方案
- 利用 xCUDA 监控 GPU 内存分配以限制离线工作负载的内存使用, 并控制内核启动来限制离线工作负载使用的计算能力
- 使用 SysMonitor 来监控 GPU 的状态, 当 GPU 状态可能影响到在线工作的实时性时, 将驱逐离线工作负载
- 提出了一种新的错误处理机制来避免传播错误
- 设计了一种基于匹配的调度算法来提高集群级别的共享效率
整体设计
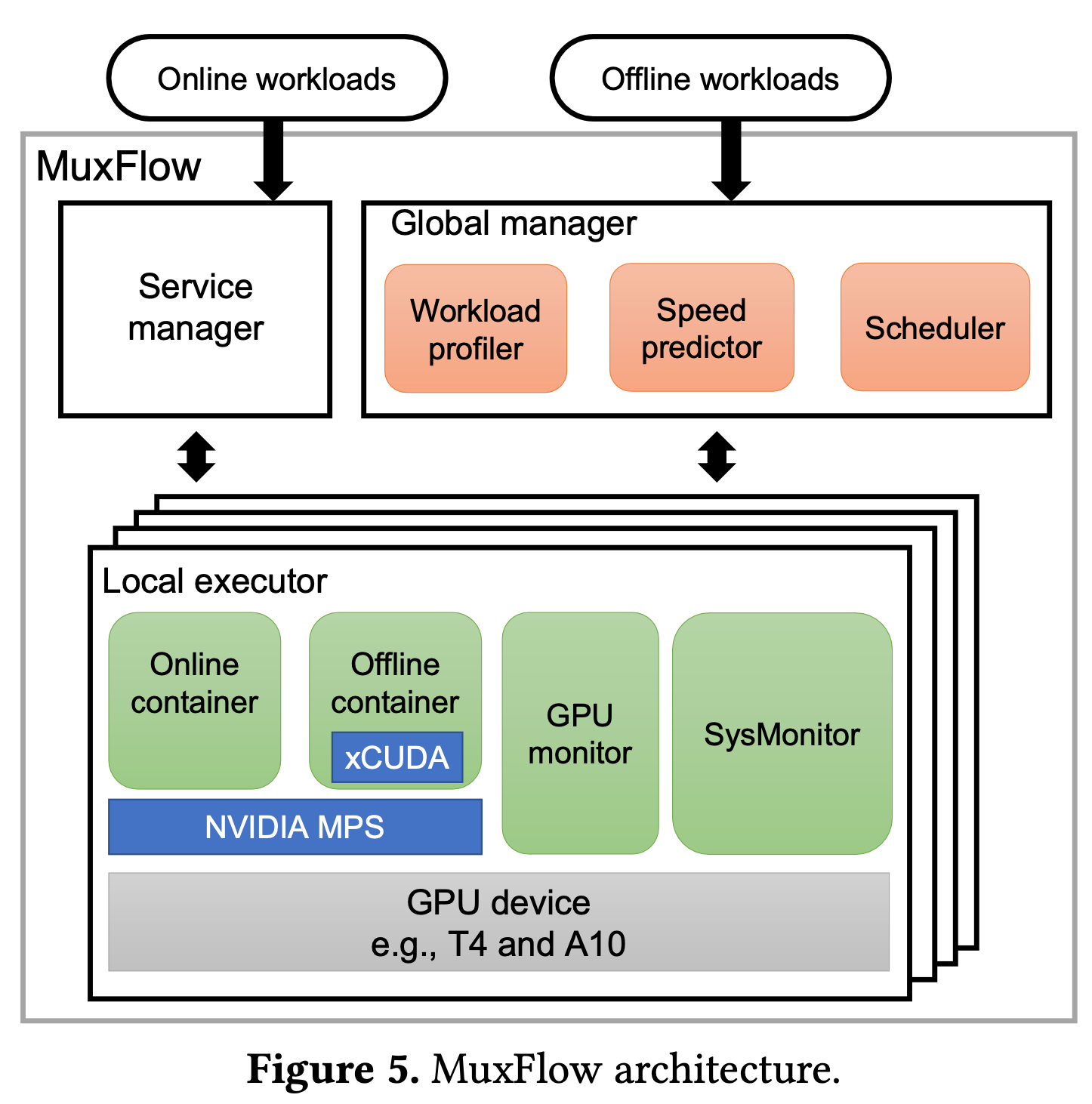
- Service Manager: 管理在线任务 (不是本文讨论的重点)
- Global Manager: 管理离线任务
- Workload Profiler: 性能分析和决策
- Speed Predictor: 利用深度学习模型预测速率并将信息传输给调度器
- Scheduler: 调度器以固定的时间间隔定期执行全局重新调度
- Local executor: 本地执行器
- Online container: 用于运行在线负载
- Offline container with xCuda: 用于运行离线负载
- GPU monitor: 定期收集 GPU 指标, SysMonitor 和 xCUDA 利用它们来管理离线 workload
- Sysmonitor: 维护一个设备状态机, 当状态机显示某一个在线 workload 受到严重影响时, sysmonitor 将驱逐离线的 workload
本文整体的调度是基于 k8s 的, 调度器的实现方式是: “We implement the scheduler as a third-party plugin to the Kubernetes scheduler.”
相关
Hyper-Q 和 MPS
Hyper-Q是一种技术,允许多个CPU线程同时将命令发送到GPU,并在GPU上并行执行这些命令。它通过将命令队列分成多个子队列,并在GPU的多个多处理器上同时执行这些子队列,从而提高了GPU的利用率。Hyper-Q使得在单个GPU上可以同时执行多个并发的工作负载,从而提高了GPU的吞吐量。
MPS(Multi-Process Service)是一种NVIDIA GPU的服务,允许多个进程共享同一个GPU。它通过在GPU上创建多个独立的工作空间,每个工作空间由一个进程使用,从而实现了GPU资源的共享。MPS可以在多个应用程序之间实现GPU资源的有效共享,但它无法保证在线工作负载的性能和安全性。
关于它们的出现先后顺序,Hyper-Q首先在NVIDIA Kepler架构的GPU中引入,而MPS则在之后的架构中被引入,如Maxwell、Pascal和Volta。Hyper-Q的目标是提高GPU的利用率和吞吐量,而MPS的目标是实现GPU资源的共享。两者可以结合使用,以进一步提高GPU集群的效率和性能。