论文略读: 综述 - A Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions
本文最后更新于:2023年11月6日 下午
- A Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions
- 2020-10, arxiv, 引用量-83
其他类似的综述文章:
- https://arxiv.org/abs/1710.09282, 引用 1110, 2017年
- https://ieeexplore.ieee.org/abstract/document/8114708, 引用 2047, 2017年
A Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions
- DNN 模型对计算、能量和存储的巨大要求使得它们在资源受限的物联网设备上的部署受到限制。 因此,近年来提出了几种压缩技术来降低 DNN 模型的存储和计算要求。
- DNN 压缩技术利用了不同视角以最小的精度妥协来压缩 DNN
- 在本文中,我们对有关压缩 DNN 模型的现有文献进行了全面回顾,以减少存储和计算需求。 基于压缩 DNN 模型的机制,我们将现有方法分为五类,即 网络剪枝(network pruning)、稀疏表示(sparse representation)、位精度(bits precision)、知识蒸馏(knowledge distillation)和其他杂项(miscellaneous)。 该论文还讨论了与每一类 DNN 压缩技术相关的挑战。 最后,我们快速总结了每个类别下的现有工作以及 DNN 压缩的未来方向
DNN 压缩的主要好处有:
- 减少存储空间 storage capacity
- 减少计算量 computation requirements
- 减少计算时间 earliness
- 更好的隐私性 privacy
- 减少能耗 enery compsumptioin
整体的分类:
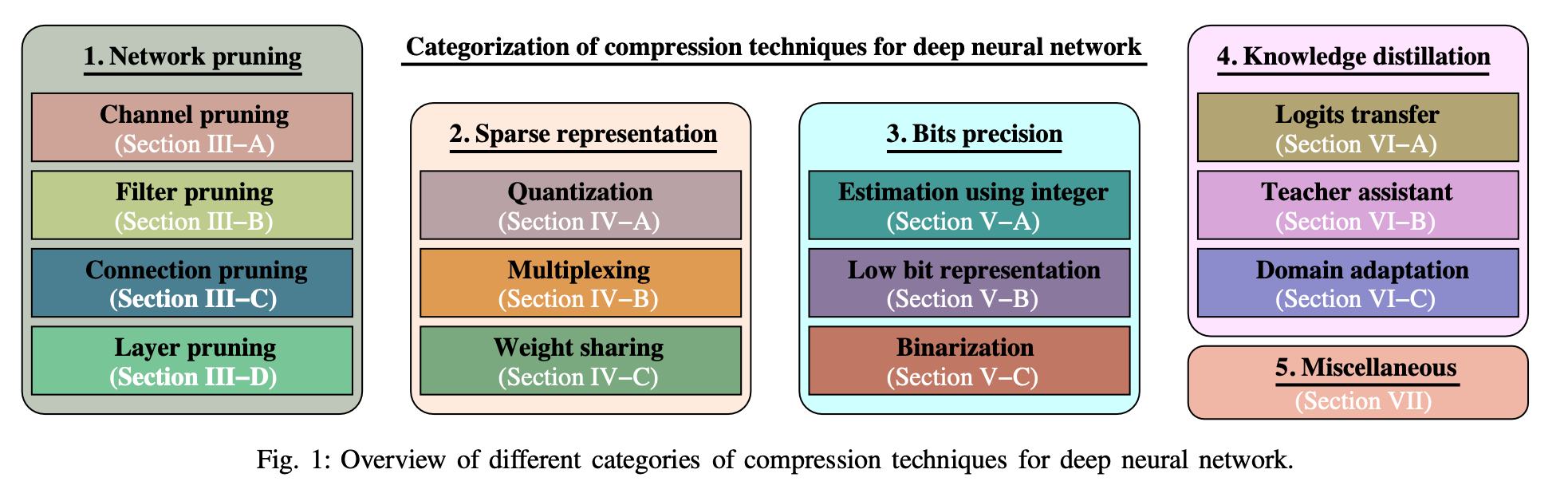
A - 网络剪枝 network pruning
Deep network pruning is one of the popular techniques to reduce the size of a deep learning model by incorporating the removal of the inadequate components such as channels, filters, neurons, or layers to produce a lightweight model. The resultant lightweight model is a low power consuming, memory-efficient, and provides faster inference with minimal accuracy compromise. The adequacy of a component relies on the amount of loss incurred when a component is removed from the model. Sometimes pruning is also said to be a binary criterion to determine the removal or persistence of a component in the DNN. The pruning is performed on a pre-trained model iteratively, such that only inadequate components are pruned from the model. We further categorized the network pruning techniques into four parts, i.e., channel pruning, filter pruning, connection pruning, and layer pruning. It helps in reducing the storage and computation requirements of the DNN model.
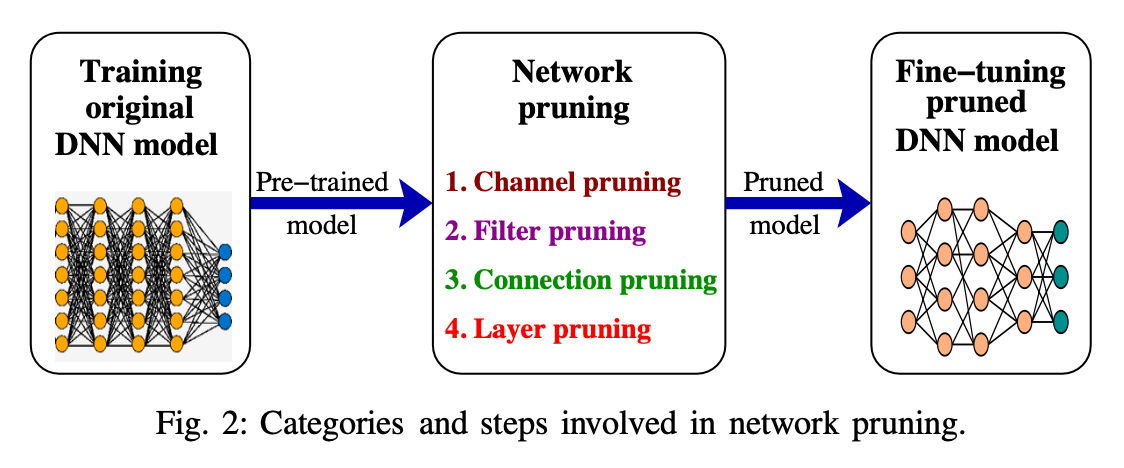
1 - 通道剪枝 (Channel pruning)
通道剪枝通过删除DNN模型中间层中冗余或不重要的通道,来降低模型的计算和存储需求,从而达到加速和压缩DNN模型的目的。
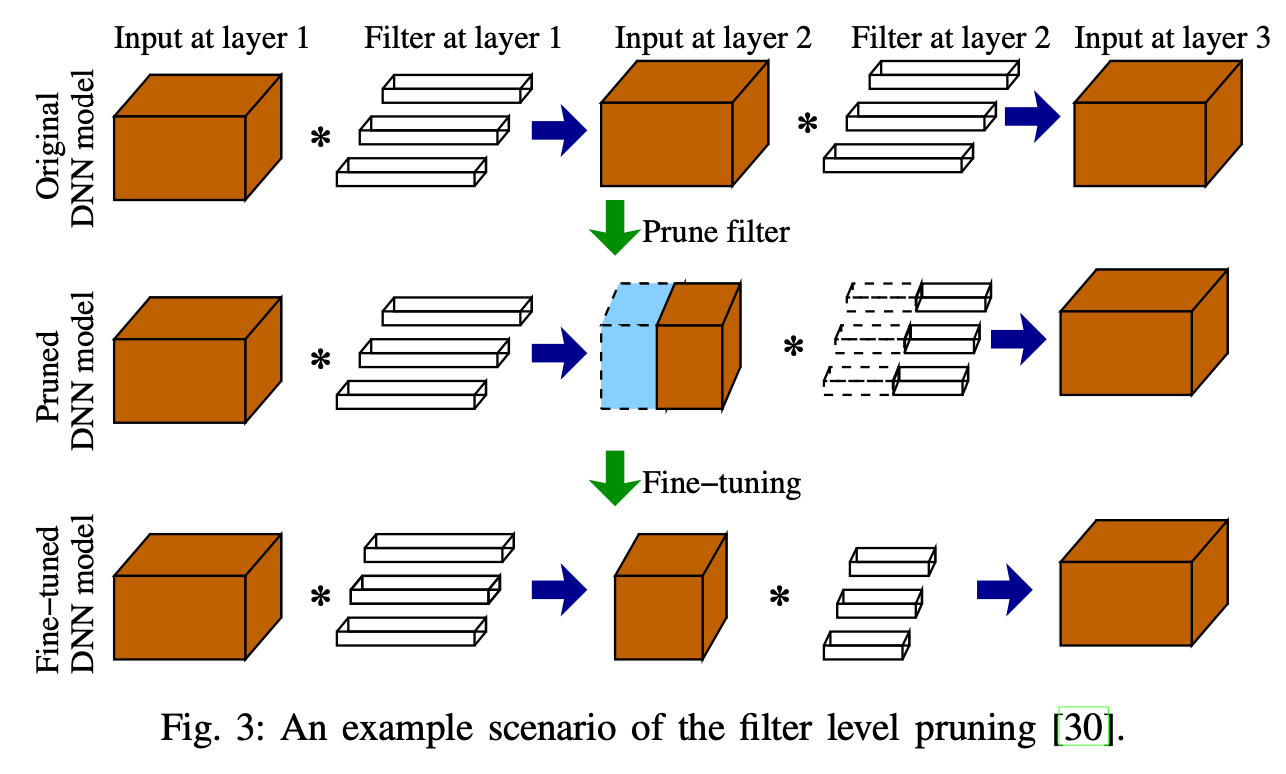
2 - 过滤器剪枝 (Filter pruning)
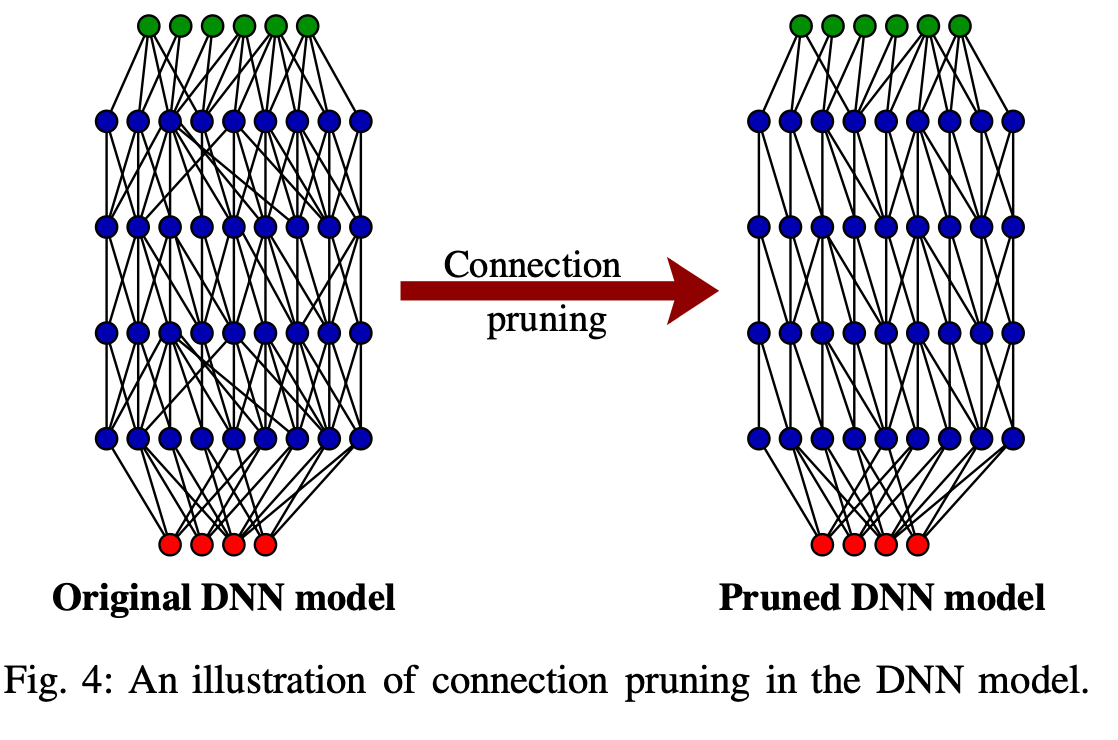
3 - 连接剪枝 (Connection pruning)
4 - 层剪枝 (Layer pruning)
通过从网络中删除一些选定的层以压缩 DNN 模型。
B - 稀疏表示 Sparse representation
1 - 量化 (Quantization)
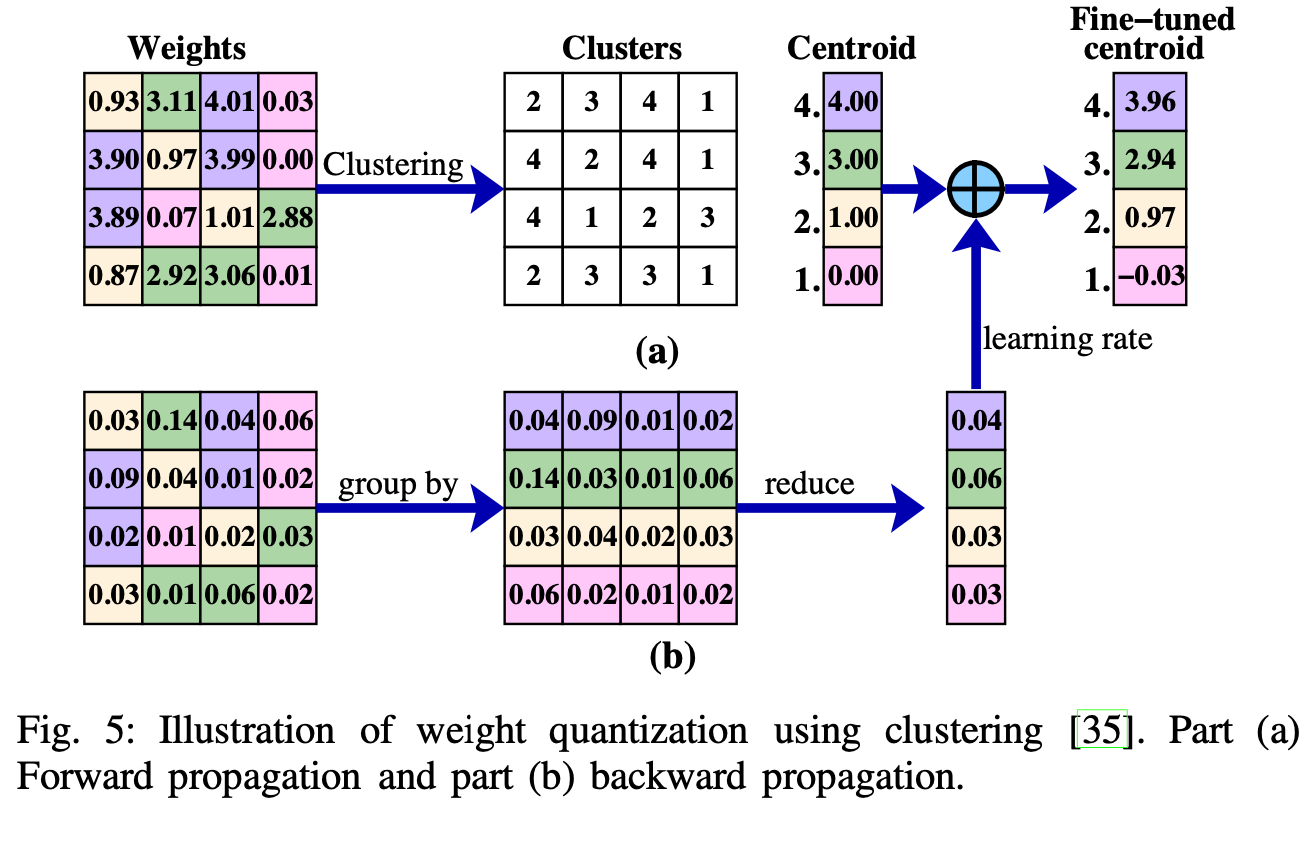
一个四个神经元的量化方式举例
2 - 多路复用 (Multiplexing)
多路复用是一种通过替换相似权重来减少DNN模型存储需求的稀疏化方法。
相关工作:
- 通过多路复用多个轻量级模型来实现在移动设备上进行低资源预算推理。
- 通过共享的backbone网络实现对不同任务的多路复用。
3 - 权重共享 (Weight sharing)
权重共享是DNN模型压缩中一个重要的方法。设计高效简单的权重共享机制,既可减少存储需求,又可降低计算复杂度
相关工作:
- 使用k-means聚类算法识别每个层中可以共享的权重。属于同一簇的连接必须共享相同的权重。作者假设不同层之间不共享权重。
- 共享训练数据的技术。数据(或权重)的共享为理解DNN的预测过程提供了帮助。但是训练时的数据共享也会导致隐私泄露。作者提出只公开少量训练数据来获取模型洞察,以减少泄露。
- 实现多任务学习来训练共享的DNN,不同的任务共享隐层权重。
C - 位精度 bits precision
1 - 整数估计 (estimation using integer)
直接使用整数计算替换浮点数计算
2 - 低精度表示 (low bits representation)
不限于 8bit 整数, 可以用任何 bit 来表示, 难点在于如何选择最佳的 bit 位数
3 - 二值化 (binarization)
D - 知识蒸馏 (knowledge distillation)
主要提出了
- Logits transfer
- Teacher assistant
- Domain adaptation
三种方式, 没仔细读